118
■ Converting scanned images to searchable text with OCR
When you scan a document, you will get a whole image of the document including signs, letters
and numbers. However, the system cannot recognize the image data as text. This means that you
are not able to search the content of your document without using OCR (Optical Character
Recognition).
You can convert such image data into searchable text data by using OCR processing ("Recognize
Text" function) of Adobe Acrobat 7.0.
Operation
1. With Adobe Acrobat, open the PDF file for conversion.
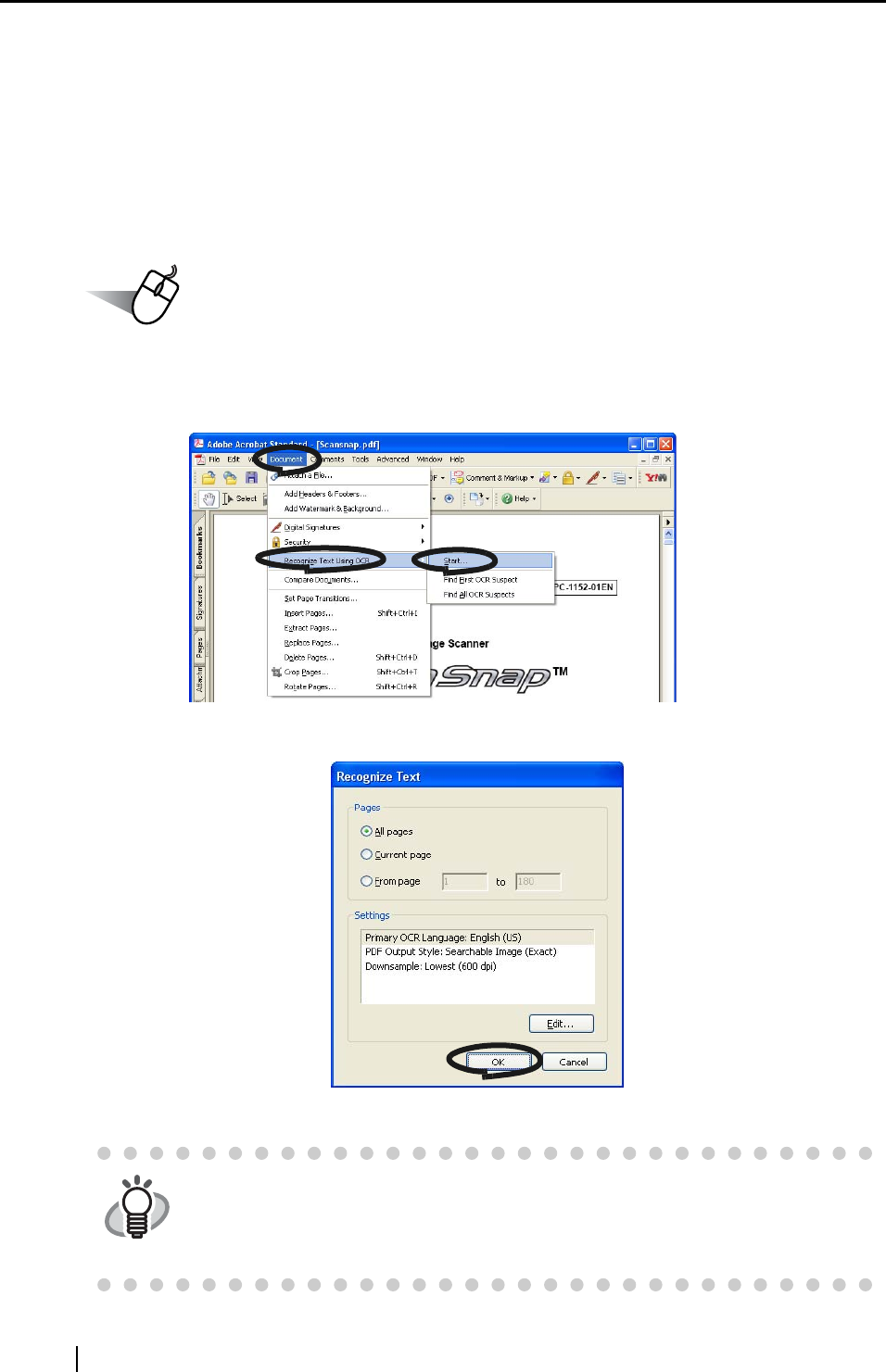
2. Select [Document] -> [Recognize Text Using OCR] -> [Start] from the menu bar.
3. In the following window, configure the necessary settings, then click the [OK] button.
⇒ The text information is added to the image data by the "Recognize Text" function.
HINT
For color documents, in the "ScanSnap Manager - Scan and Save Settings"
dialog box, select [Scanning] tab -> "Image quality" -> "Better (Faster)" or "Best
(Slow)" and scan.
For details of this function, refer to "Adobe Acrobat 7.0 Help."





































































































































































































